
Dado que los archivos de Excel son una de las entidades más comúnes en cuanto se refiere a almacenamiento de datos, el poder convertirlos o abrirlos en otros programas siempre es algo que nos vendrá útil. En este caso, vamos a mostrar cómo analizar con Power Automate un archivo de Excel y hacer que se lea cada una de sus filas. Para poder ahondar bien en este tema, lo vamos a dividir en dos secciones:
- Analizar un archivo de Excel en Power Automate (Flujo de MS)
- Extraer información de un archivo GRANDE de Excel en Power Automate (Flujo de MS)
ANALIZAR ARCHIVO DE EXCEL EN POWER AUTOMATE
Este proceso es bastante sencillo de lograr con Power Automate. Por defecto, nosotros tenemos una acción, llamada «Lista de filas presentes en una tabla».
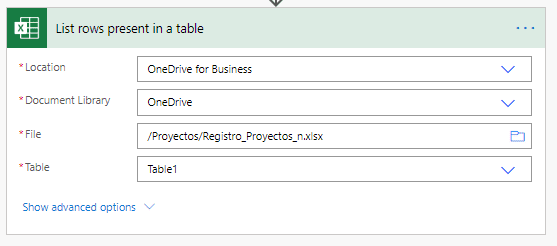
Como podemos observar, en sus opciones básicas obtenemos cuatro parámetros:
- Ubicación: es el URL del sitio de SharePoint en donde está almacenado nuestro archivo de Excel
- Directorio del documento: es el nombre de la biblioteca del documento
- Archivo: aquí seleccionamos el nombre del archivo
- Tabla: aquí seleccionamos cuál tabla queremos que sea analizada del archivo de Excel
Con proveer estos cuatro parámetros, nuestro Flujo será capaz de analizar el archivo de Excel designado. Es importante tomar en cuenta que para analizar tablas en un archivo de Excel, los datos deben estar definidos en una tabla.
Si no sabes cómo definir tu rango como tabla, revisa esta entrada.
Y si te gustaría aprender a usar la herramienta, puedes checar nuestro curso con licencia aquí.
EXTRAER INFO DE ARCHIVOS GRANDES DE EXCEL EN POWER AUTOMATE
El método anterior nos servirá bien para archivos pequeños, pero solo archivos pequeños. Si nuestro archivo de Excel tiene más de 5,000 filas, entonces este método no nos funcionará. De hecho, y por defecto, tan solo analizará 255 filas.
Para leer todas las filas de un archivo de Excel grande, necesitamos leer datos recursivamente por montones, tal y como se explica en este diagrama de flujo:

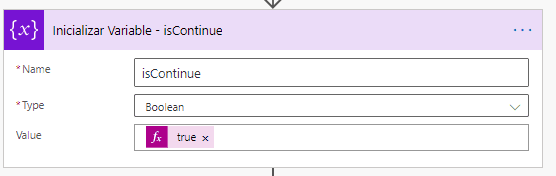
Iniciaremos con una variable «isContinue» para indicar si queremos o no que busque más filas de Excel. Este valor lo tendremos por defecto como true.
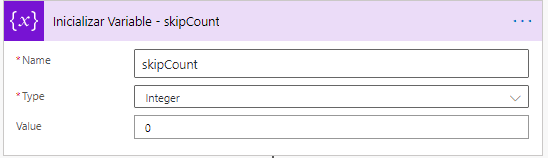
Iniciaremos otra variable, «skipCount». Esta denotará el número de filas a saltar. Por defecto el valor estará establecido en cero, pero tras descargar cada conjunto de filas, se irá incrementando este valor.
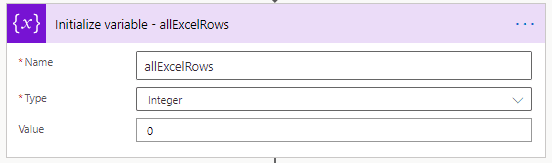
Y una ultima variable que nos permitira contar las filas por cada batch.
Ahora viene el elemento más crucial, «Do until». Para esto, habrá que especificar primero la condición de quiebre, como lo puede ser el cuándo se acabe este loop. Para este caso, cuando la variable «isContinue» se vuelva falsa, entonces podemos acabarlo.
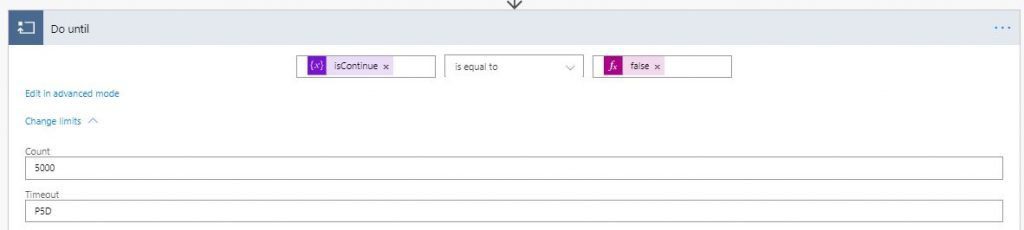
Antes de proceder, hay que cambiar los límites por defecto de «Do until». Aquí hemos establecido la cuenta a 5000 y el tiempo límite a P5D, que son cinco días.
El bloque Do para grándes archivos de Excel
A continuación usaremos «Lista de filas presentes en una tabla» para descargar el primer montón de 5,000 filas. Antes de usar nuestra lógica, necesitaremos cambiar el ajuste de esta acción para que haga paginación:
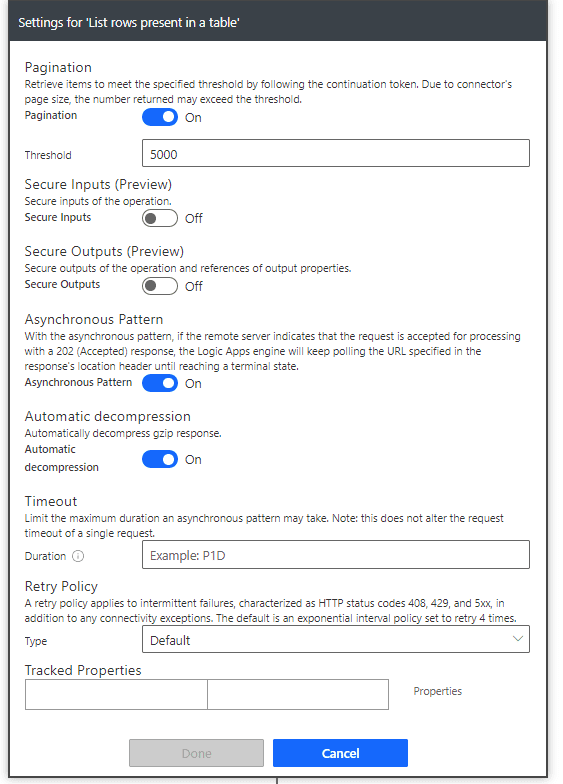
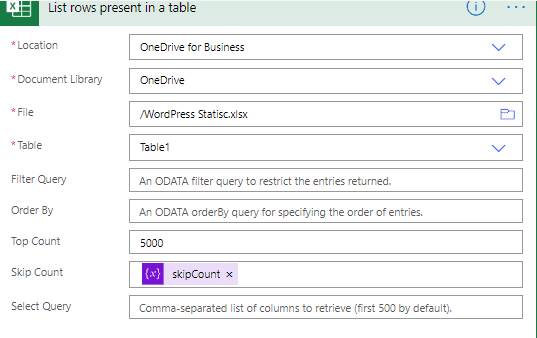
La configuración básica de esta acción «Lista de filas presentes en una tabla» deberá ser tal y como se mostró en el primer método, con la diferencia de que vamos a modificar sus configuraciones avanzadas. Estableceremos el conteo máximo a 5,000 (pues es el máximo posible) y «saltar cuenta» a nuestra variable dinámica «skipCount», la cual será cero por defecto. En pocas palabras, pediremos que nos dé las primeras 5,000 filas del archivo de Excel. La próxima vez pediremos que descargue de la 5,001 a la 10,000 y así seguiremos tanto como sea necesario.
Una vez que las filas hayan sido buscadas, revisaremos si la cuenta de filas descargadas es igual a 5,000 o si es menos. Si la cuenta es de 5,000, entonces puede que haya más filas que necesiten ser descargadas; de resultar menos de 5,000, entonces podremos estar seguros de que este es el último montón y que no hay más filas para descargar.
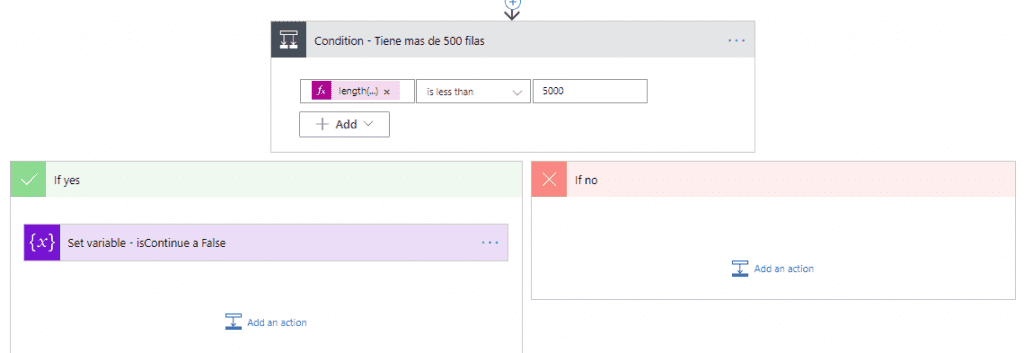
Para poder hacer esto bien, vamos a calcular el largo del valor de propiedad de la acción anterior.
length(body('List_rows_present_in_a_table')?['value'])Procesar el primer bloque y repetir
Aquí podemos usar «aplicar a cada una» para procesar cada fila de Excel que se descargó. En este caso, solo vamos a estar incrementando el valor del contador de fila.
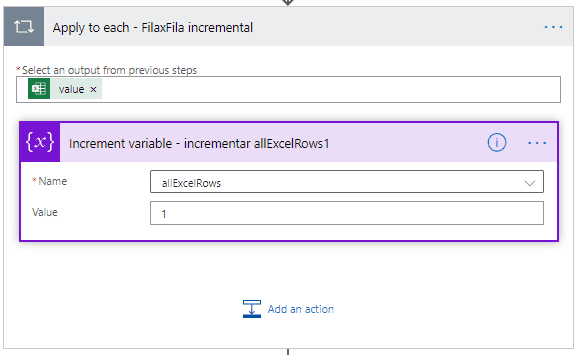
Nota: En nuestro flujo, aquí es donde deberemos escribir la lógica para procesar cada una de las filas de Excel. Recuerda cambiarlo por el que necesites.
Por último, vamos a incrementar la variable del valor de contador «skipCount» a 5,000. Por lo cual, para descargar el siguiente montón de 5,000 filas:
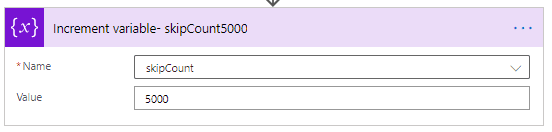
De todo este proceso podemos notar varias cosas, como que estos métodos son muy específicos, por lo que hay que ser claros a la hora de introducir las rutas y nombres de los archivos para que se puedan hacer los análisis en los archivos correctos. También podemos notar que, por defecto, solo un número pequeño de filas será regresado, lo cual puede sernos útil en la mayoría de los casos.
Para archivos grandes, necesitamos descargar las filas de manera secuencial, y cada grupo no debe ser mayor a 5,000 filas. Es importante mencionar también que con este método solo se pueden leer datos desde una tabla de Excel, por lo que no se podrán analizar filas simples.
Puedes mejorar la velocidad de tu flujo haciendo algo similar al video.
Cualquier duda nos leemos abajo.
